- 小说 星座 交友 视频 明星 新闻 NBA 足球 体育 美图 游戏 音乐 摄影 军事 笑话
- 社区 招聘 地图 美食 汽车 基金 两性 女性 法律 娱乐 时尚 彩票 宠物 股票 手机
- 购物 健康 银行 房产 儿童 旅游 大学 宗教 公益 考试 教育 外语 留学 科技 爱好
- 微博 电脑 桌面 招商 聊天 硬件 软件 建站 编程 邮箱 设计 数码 曲艺 棋牌 生活
- QQ 二手汽车 生活助手 天气 直播 站长 婚嫁 租厂房 服务器 租赁 互联网 农产品 修理 搬家 UI素材
- 保洁 面辅料 牧业 出书 代工 物流 电影 电视 综艺 动漫 全知导航-八卦 秀场 减肥 美女 母婴
- 团购 特卖 家居 杀毒 手机应用 找加盟 找设计 找家政 众筹 找搬家 找代理 热门应用 找代工 找工作 找物流
- 找回收
关键词:PaLM-E,模型,机器人,语言,谷歌,任务,研究,视觉中,能力
相同的PaLM-E模型通过具有复杂序列的任务自主控制机器人
划重点:
- 1PaLM-E是迄今为止已知的最大VLM(视觉语言模型)。作为一种多模态具身VLM,它不仅可以理解图像,还能理解、生成语言,执行各种复杂的机器人指令而无需重新训练。它还展示出了强大的涌现能力(模型有不可预测的表现)。
- 2通过将PaLM-E集成到控制回路中,它可以抵抗任务期间可能发生的中断。在一个视频示例中,研究人员从机器人手中抓取薯片并移动它们,但机器人找到薯片并再次抓取它们。

“距AGI(通用人工智能)的问世不会太遥远,不过过程中肯定会出现许多误判。预计在未来五年时间里,AI能够在大多数人类目前从事的工作上表现得比人类更好。”在ChatGPT发布前一个月,OpenAI联合创始人、ChatGPT项目的主要负责人John Schulman在强化学习播客《TalkRL》上说道。
AGI似乎并不遥远,但对于如何通向AGI,目前研究者都还在探索。就在近日,一个新的研究成果发布——用视觉数据来增强语言处理能力。它的表现令人惊喜,展示出了强大的涌现能力(模型有不可预测的表现)。
北京时间3月7日,谷歌和柏林工业大学的团队重磅推出了史上最大的视觉语言模型——PaLM-E,参数量高达5620亿(GPT-3的参数量为1750亿)。
 PaLM-E的应用示意
PaLM-E的应用示意
“PaLM-E是迄今为止已知的最大VLM(视觉语言模型)。我们观察到诸如多模态思维链推理(允许模型分析包括语言和视觉信息的一系列输入),只接受单图像提示训练的多图像推理(使用多个图像作为输入来做出推理或预测)等涌现能力。”论文的第一作者、谷歌AI研究员Danny Driess说。
 论文的第一作者、谷歌AI研究员Danny Driess的推文
论文的第一作者、谷歌AI研究员Danny Driess的推文
在这个意义上,随着时间推移,深度学习模型变得越来越复杂,PaLM-E似乎延续了“产生惊喜”的这个趋势。
PaLM-E(Pathways Language Model with Embodied )是PaLM-540B语言模型与ViT-22B视觉Transformer模型的结合。它被称为“PaLM-E”是因为它基于谷歌现有的 “PaLM”大语言模型 (类似于ChatGPT背后的技术)。谷歌通过添加感官信息和机器人控制,使PaLM“具身化(embodiment,与身体联系紧密的状态)”。由于它基于语言模型,PaLM-E会进行连续观察,例如图像信息或传感器数据,并将它们编码为一系列与语言标记大小相同的向量。这允许模型以与处理语言相同的方式“理解”感官信息。PaLM-E还借鉴了谷歌之前在ViT-22B视觉Transformer模型上的工作,ViT-22B已经接受过各种视觉任务的训练,例如图像分类、对象检测、语义分割和图像字幕。
谷歌并不是唯一一个致力于使用神经网络进行机器人控制的研究小组。这项特殊的工作类似于微软最近的“ChatGPT for Robotics”论文,该论文尝试以类似的方式将视觉数据和大型语言模型结合起来进行机器人控制。
作为一种多模态具身视觉语言模型(VLM),PaLM-E不仅可以理解图像,还能理解、生成语言,可以执行各种复杂的机器人指令而无需重新训练。
 机器人被要求去抽屉里拿薯片
机器人被要求去抽屉里拿薯片
根据谷歌的说法,当给出一个高级命令时,比如“把抽屉里的薯片拿给我”,PaLM-E可以为一个有手臂的移动机器人平台(由谷歌机器人开发)生成一个行动计划并执行自己的行动。
PaLM-E通过分析来自机器人相机的数据来实现这一点,而无需对场景进行预处理。这消除了人类预处理或注释数据的需要,并允许更自主的机器人控制。它还具有弹性,可以对环境做出反应。例如,PaLM-E模型可以引导机器人从厨房取薯片袋,而且,通过将PaLM-E集成到控制回路中,它可以抵抗任务期间可能发生的中断。在一个视频示例中,研究人员从机器人手中抓取薯片并移动它们,但机器人找到薯片并再次抓取它们。
在另一个示例中,相同的PaLM-E模型通过具有复杂序列的任务自主控制机器人,这些任务以前需要人工指导。谷歌的研究论文解释了PaLM-E如何将指令转化为行动:
我们展示了PaLM-E在具有挑战性和多样化的移动操作任务上的性能。机器人需要根据人类的指令规划一系列导航和操纵动作。例如,给出指令“我把饮料弄洒了,你能给我拿点东西来清理吗”,机器人需要规划一个包含“1. 找到海绵,2. 捡起海绵,3. 拿来,4.放下海绵”的序列给用户。受这些任务的启发,我们开发了3个用例来测试PaLM-E的具身推理能力:可供性预测、故障检测和长期规划。
 PaLM-E识别图像中的篮球明星科比·布莱恩特,并可以生成关于他的文本信息,比如他赢得了多少次冠军
PaLM-E识别图像中的篮球明星科比·布莱恩特,并可以生成关于他的文本信息,比如他赢得了多少次冠军
研究人员写道,PaLM-E也是一种“有效的视觉语言模型”。例如,它可以识别图像中的篮球明星科比·布莱恩特,并可以生成关于他的文本信息,比如他赢得了多少次冠军。在另一个例子中,PaLM-E看到一个交通标志并解释与之相关的规则。
 PaLM-E看到一个交通标志并解释与之相关的规则
PaLM-E看到一个交通标志并解释与之相关的规则
除了机器人技术,谷歌研究人员还观察到一些有趣的效果,这些效果显然来自PaLM-E的核心——大型语言模型。PaLM-E表现出了“正迁移”能力,即它可以将从一项任务中学到的知识和技能迁移到另一项任务中,从而与单任务机器人模型相比具有“显着更高的性能”。
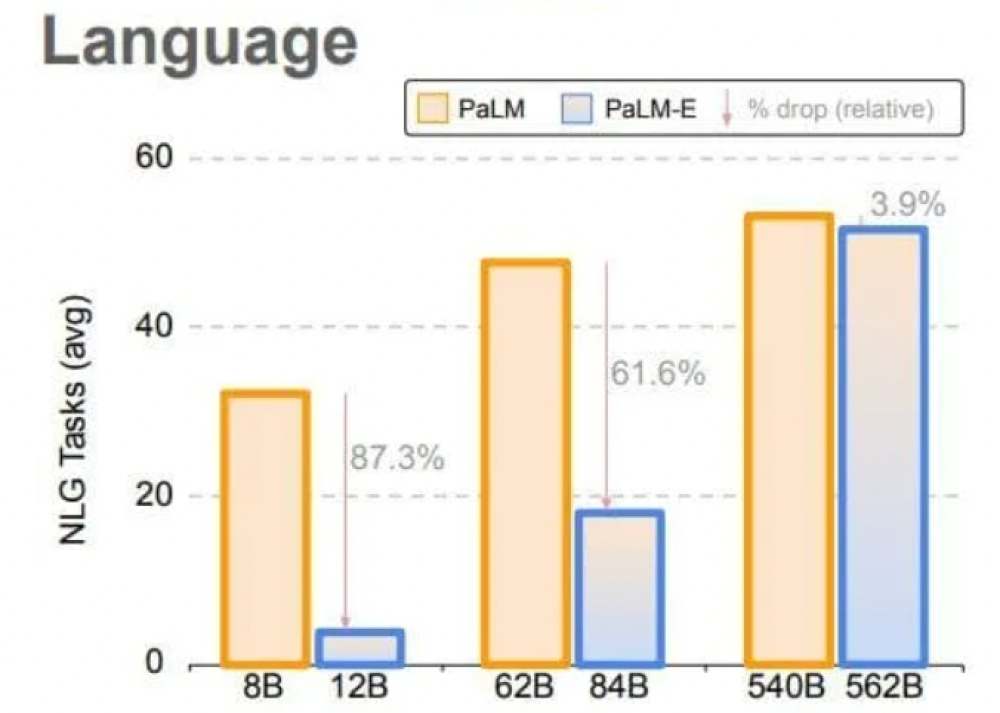 语言模型越大,在视觉语言和机器人任务训练时就越能保持其语言能力
语言模型越大,在视觉语言和机器人任务训练时就越能保持其语言能力
此外,他们还观察到模型规模的趋势:“语言模型越大,在视觉语言和机器人任务训练时就越能保持其语言能力——从数量上讲,562B PaLM-E模型几乎保留了其所有的语言能力。
谷歌研究人员计划探索PaLM-E在现实世界场景中的更多应用,例如家庭自动化或工业机器人。他们希望PaLM-E能够激发更多关于多模态推理和具身AI的研究。
“多模态”已成为一个流行语,我们可能会越来越多地听到这个词。因为很多公司正在研发看起来能够像人类一样执行一般任务的通用人工智能。
博主提醒,网络非法外之地,请文明理性发言。

©2010-2019 全知导航-网址全搜罗,
资讯全知道。
苏ICP备10224953号-2
网友评论仅供其表达个人看法,并不表明全知头条立场。请理想发言,恶性发现将由个人承担全部责任。